

Aujourd’hui, on va voir comment faire un déploiement automatique (Continuous Deployment, CD pour la suite) au push sur une branche de Gitlab.
Alternatives à Gitlab
Tout d’abord quelques alternatives à Gitlab CI, il y en a beaucoup d’autres.
- Travis CI
- CircleCI
- Jenkins
- Bamboo
- …
Alternatives à AWS
Vous pouvez brancher n’importe quoi comme système de déploiement, du moment que vous arrivez à lancer le déploiement depuis un containeur Docker.
Vous ne savez pas faire du Docker ? Ce n’est pas grave, il y en a qui travaille pour vous : https://hub.docker.com
Il y a de toute les technos, Capistrano, Ansistrano, Deployer, Chef, Puppet, Ansible, Rsync, SSH…
Il n’y a pas votre techno ? Payez un presta pour vous le faire !
Projet de test
Rien de fou pour ça, on va installer un micro-framework : Lumen, voici la procédure d’installation.
composer create-project --prefer-dist laravel/lumen blog
cd blog
git init
git remote add origin [email protected]:Lumao/blog.git
git add .
git commit -m "Initial commit"
git push -u origin master
Et voilà !
Pourquoi ne pas faire un simple fichier html ? Tout simplement pour faire plusieurs étapes dans notre déploiement.
Configuration AWS
La partie la plus complexe, l’interface n’est pas la plus simple à utiliser.
Voici l’url : https://aws.amazon.com/fr/console/
Je pars du principe que vous avez un compte et que vous connaissez un minimum le système.
Avertissement : AWS est un service payant, les actions à faire coûtent de l’argent, et la facture peut-être lourde. Réfléchissez avant de cliquer et couper les services quand vous n’en avez plus l’utilitée.
On va accéder à chaque service via la recherche.
S3
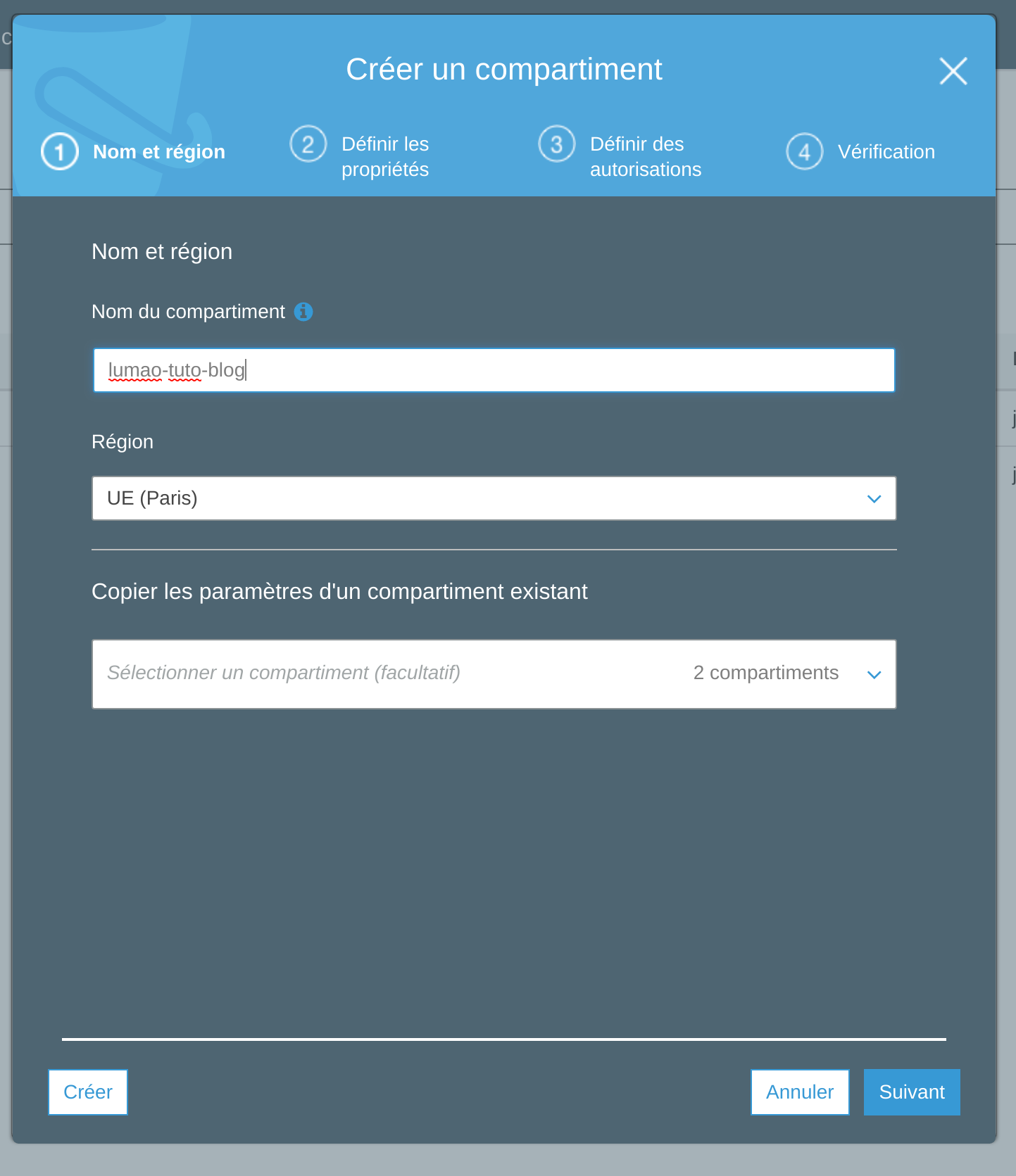
Créer un compartiment
On va créer un compartiment avec le nom lumao-tuto-blog.
Ajouter un fichier dans le compartiment S3
Depuis la liste, on clic sur le nouveau compartiment créé,
On upload un fichier app.zip.
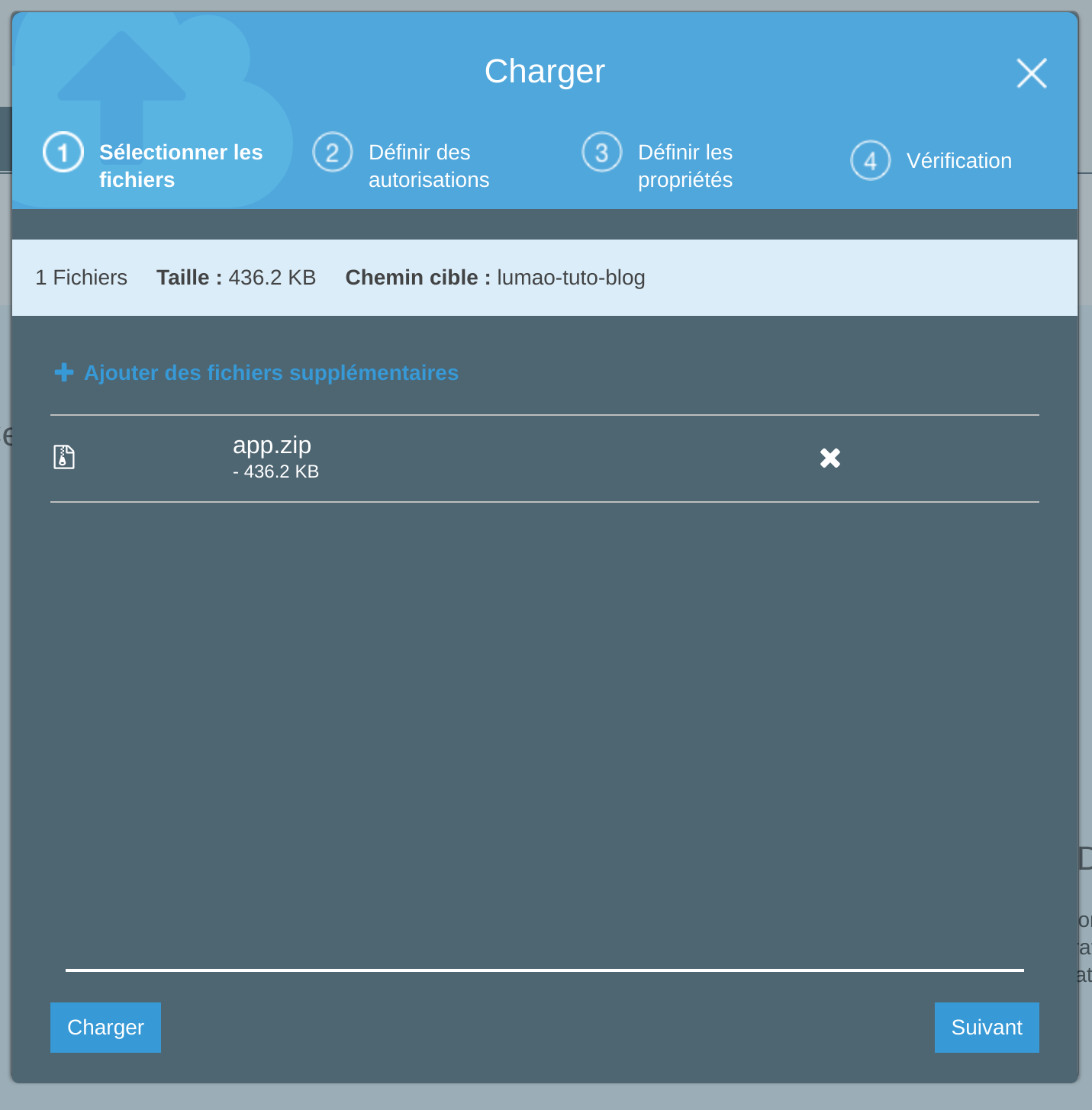
On clic dessus pour voir le détail
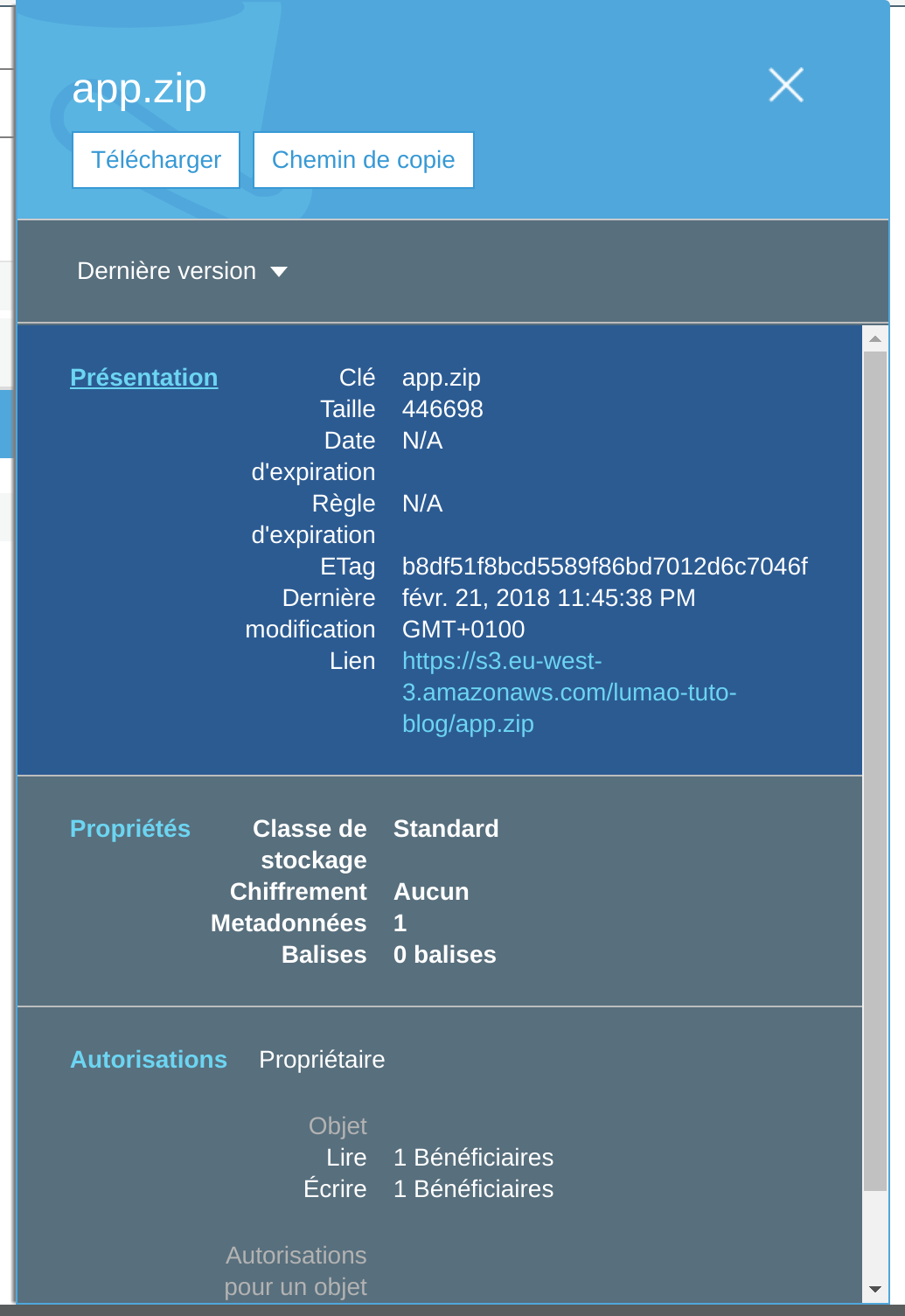
On copie-colle le lien, pour moi : s3.eu-west-3.amazonaws_com/lumao-tuto-blog/app.zip
On le garde dans un coin, on en aura besoin après.
Elastic Beanstalk
Créer un environnement
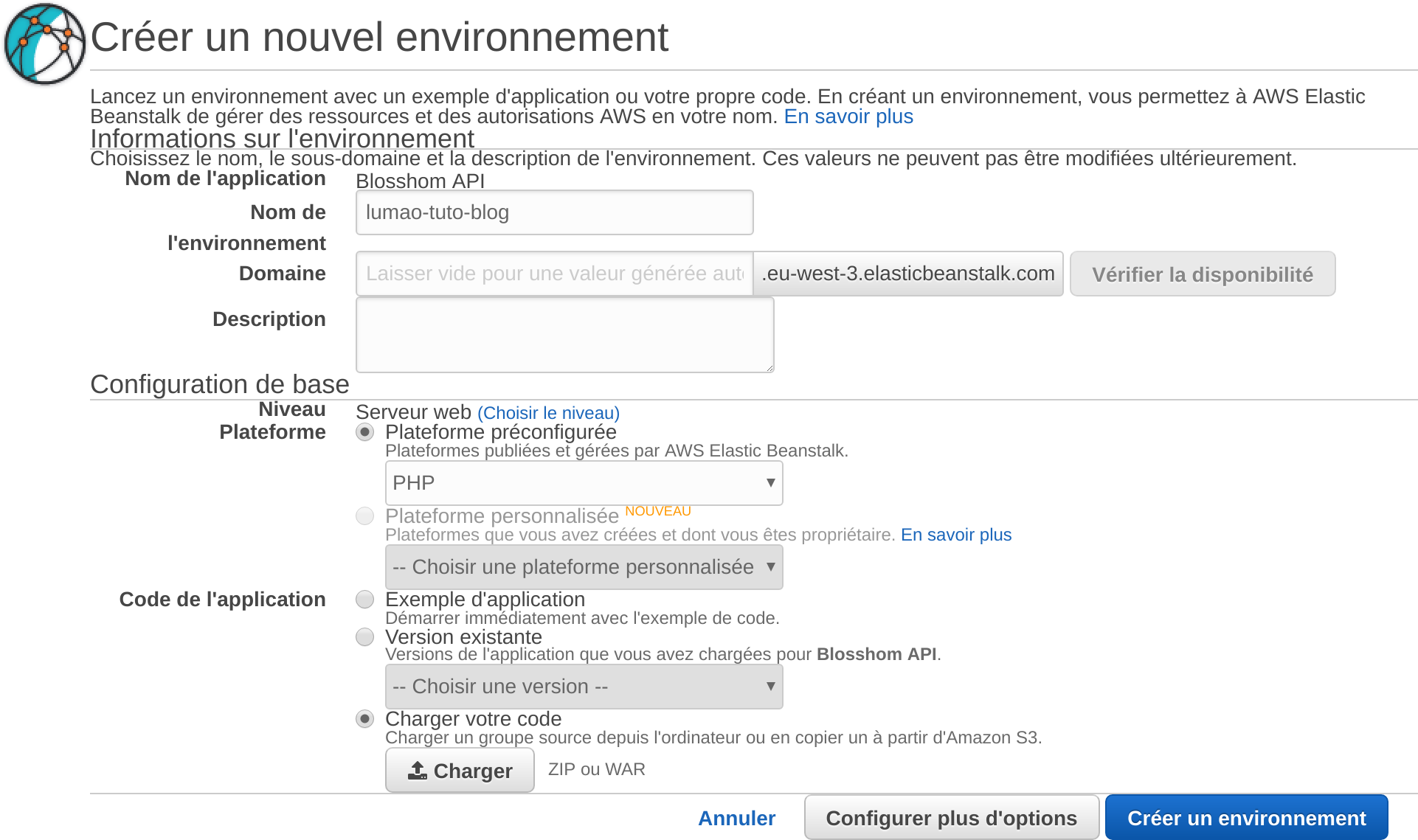
On charge les sources
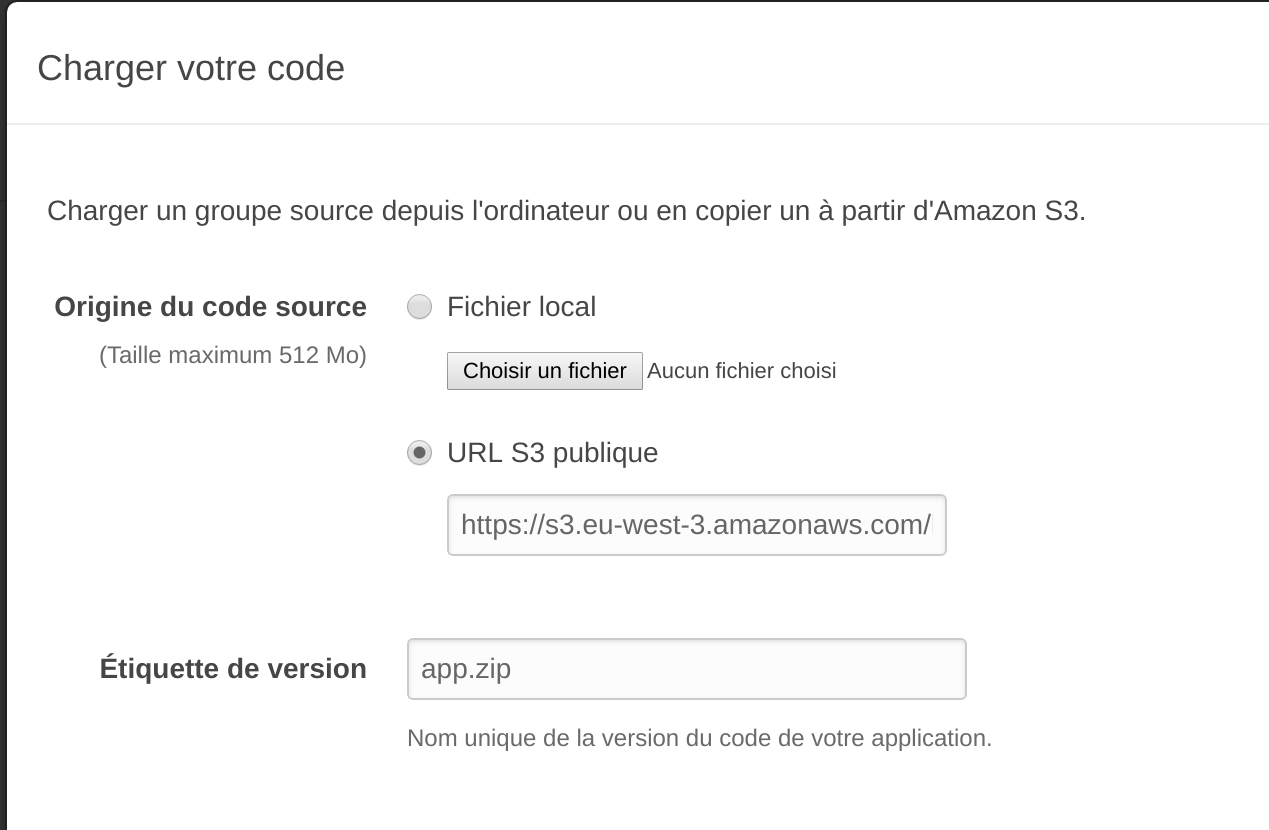
On clic sur Créer un environnement
On attend quelques minutes puis l’environnement est dispo.
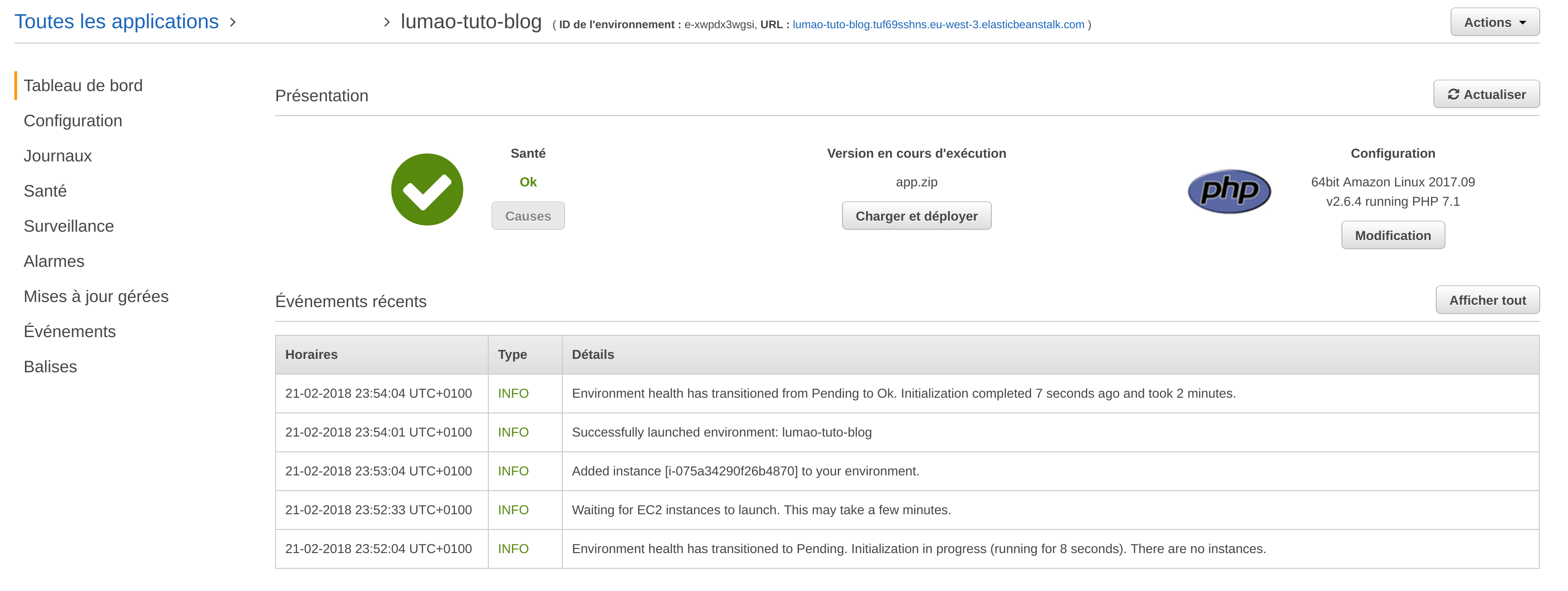
En haut à droite, on voit l’url, ici : http://lumao-tuto-blog.tuf69sshns.eu-west-3.elasticbeanstalk.com/
IAM

Ajouter les droits :
- AmazonS3FullAccess
- AWSElasticBeanstalkFullAccess
Ce n’est pas très sécurisé mais ça ira pour aujourd’hui. Tuto IAM sur Google pour la suite !
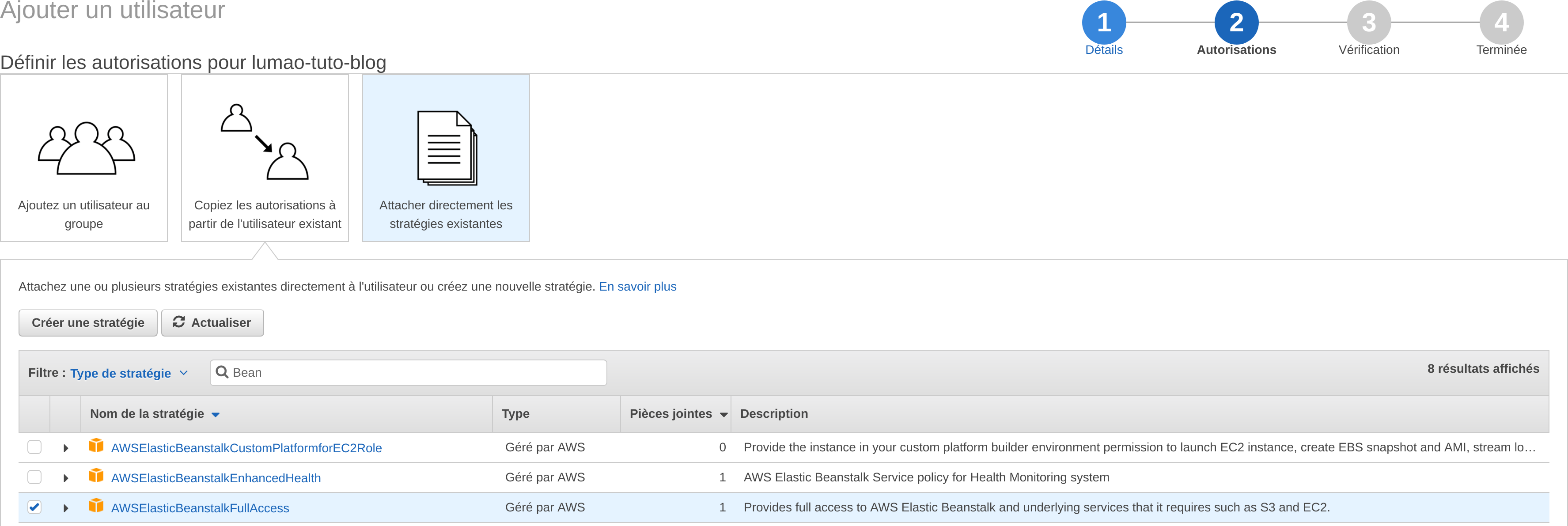

Vous avez maintenant vos clés d’accès.

- ID : AKIAISWWDEGU67CCU6IQ
- Password : PB8OZq5k6aHjXfaaEs+ifr38GzIMFvuBj2k+7t4y
Il ne faut pas partager ces clés, elles sont très importantes. Je les ai bien sûr désactivées avant de mettre en ligne ce tuto ;)
Récapitulatif Amazon
On a maintenant un environnement élastique, qui déploie un fichier zip quand on lui demande (via un clic sur un bouton ou via l’API).
Le déploiement se fait sur un environnement qui s’adapte tout seul à la charge en cours. Si vous avez “beaucoup” de trafic, au lieu d’avoir un serveur, vous pouvez en avoir 5, la seule limite est votre portefeuille. Potentiellement sur plusieurs zones géographiques.
Gitlab CI
Je vais essayer de résumer quelques fonctions de Gitlab pour le CD.
Une “grosse” partie de l’interface la gestion de cluster Kubernetes, ça ne sera pas pour aujourd’hui.
Concept généraux
Une pipeline est un groupe de jobs exécutés par stage (étapes).
Toutes les tâches d’une étape sont exécutées en parallèle (si possible), et si elles réussissent toutes, le pipeline passe à l’étape suivante.
Si l’un des jobs échoue, l’étape suivante n’est (habituellement) pas exécutée.
Pipelines
Voici ce qu’on va faire :
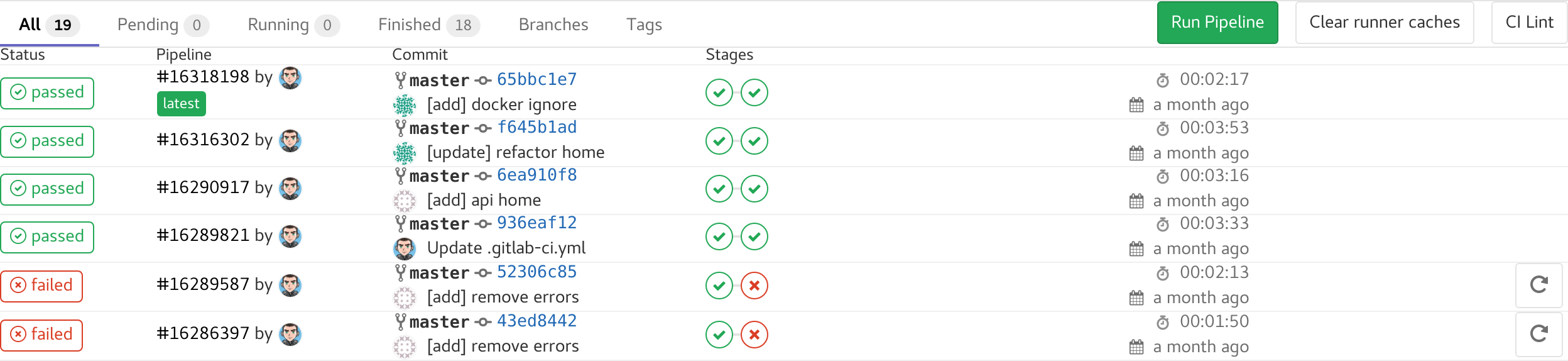
Sur un projet un peu plus actif :
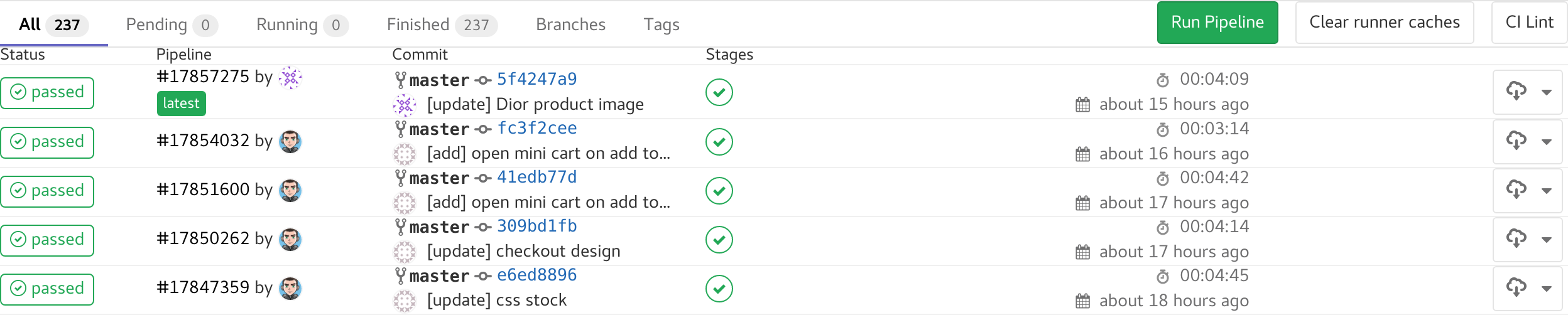
On voit l’état de la pipeline, qui l’a lancé, sur quel commit et le status de chaque stage. Il y en a certaines qui ne sont pas passé et si on va dessus, on verra le message d’erreur.
Jobs
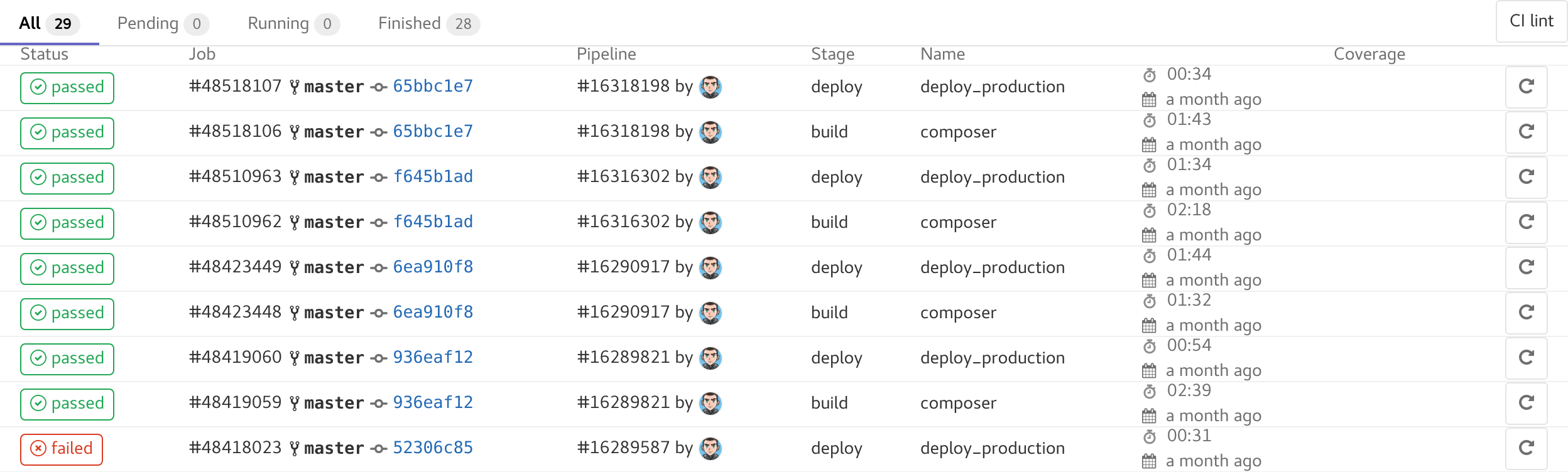
On voit le détail de chaque job.
Schedules

On peut déployer automatique suivant une crontab, ici une fois par semaine la branche master.
Environments
Liste des environnements avec url.

On voit la liste des pipelines qui ont été fait, on peut faire un rollback à une ancienne version ou re-deployer la version en cours.
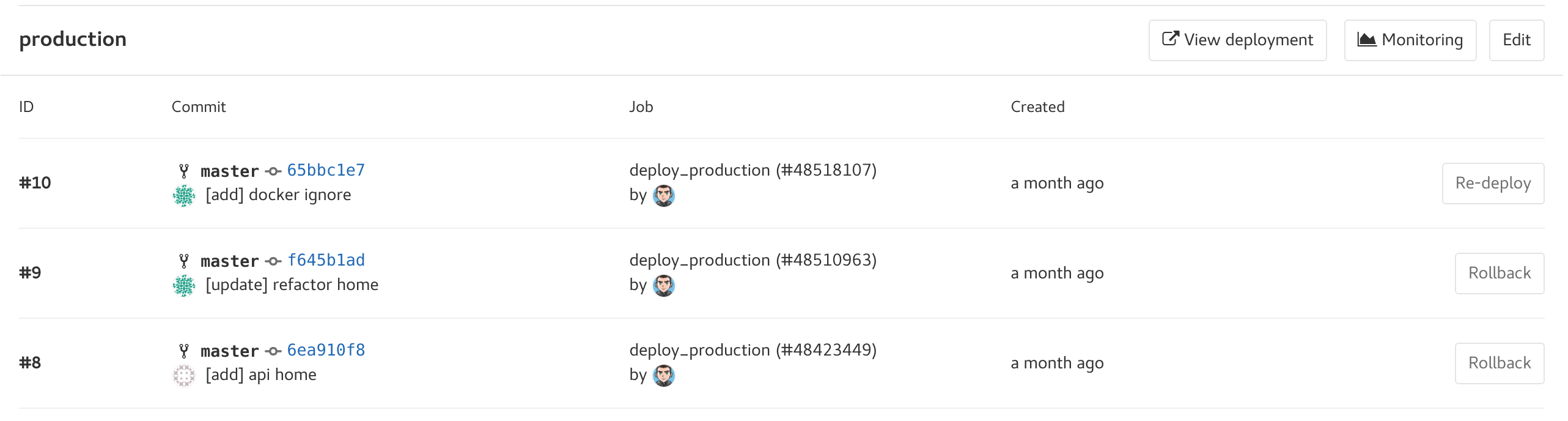
Charts
Je triche, c’est sur un autre projet qui est légèrement plus actif :)
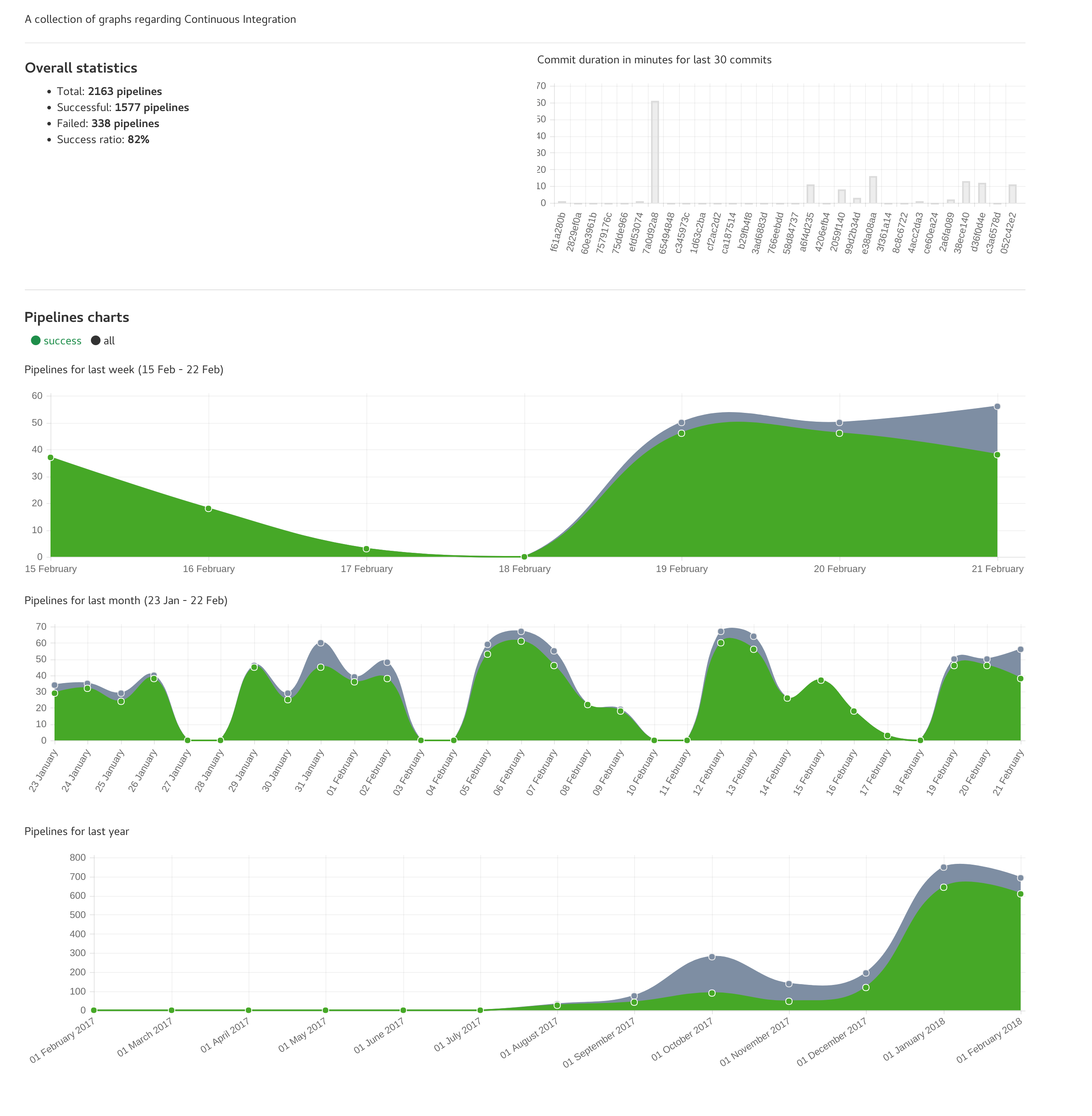
CI
La question que tout le monde se pose : comment on fait ça ? Facile, il suffit d’un fichier…
.gitlab-ci.yml
stages:
- build
- deploy
composer:
image: lavoweb/php-7.0
stage: build
script:
- curl -s https://getcomposer.org/installer | php
- php composer.phar install –no-ansi –no-dev –no-interaction –no-progress –no-scripts –optimize-autoloader
Deployment - Production
deploy_production:
image: lavoweb/aws-cli
stage: deploy
when: manual
script:
- rm -R .* *.md *.xml test/ composer.* 2>/dev/null
- zip myapp.zip -r .
- aws s3 cp ./myapp.zip s3://$AWS_BUCKET
- aws elasticbeanstalk rebuild-environment --environment-id $ELASTICBEANSTALK_ENVIRONMENT
environment:
name: production
url: https://api.blosshom.com
only:
- master
cache:
untracked: true
paths:
- vendor/
Et voilà !
On a 2 étapes dans la CI :
- build. On crée tous les fichiers dont on a besoin
- deploy. On déploie sur AWS Beanstalk
La première (build) consiste à faire un composer install. On part de l’image docker lavoweb/php-7.0, on télécharge le .phar de composer et on le lance.
La seconde étape (deploy) consiste à zipper les sources, copier le fichier sur S3 et enfin refaire notre environnement Beanstalk. Pour ça, on utilise l’image docker lavoweb/aws-cli.
Comme vous le voyez, on n’utilise pas la même image, vous vous doûtez bien qu’il ne va pas garder les fichiers. Dans la CI, on peut jouer une analyse de code, puis lancer les tests unitaires et enfin lancer le déploiement. Il faut activer une option pour garder les fichiers, c’est l’instruction cache.
Vous avez sûrement remarqué qu’il y a quelques variables dans le script.
Ce sont les accès aux différents services. Il ne faut surtout pas les mettre dans le code, n’importe qui pourrait y avoir accès.
Pour éviter ça, Gitlab dispose d’une gestion des secrets. C’est dans Settings => CI / DI => Secret variables.

Vous pouvez avoir des configurations différentes par environnement.
Et le mieux ? C’est que ça marche avec plein de techno, ce site est déployé via Travis CI + Hugo.